
勉強の過程で登場した、”torch.Tensor.scatter_”という関数。公式にはその動作について以下のような記述があります。
self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0 self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1 self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2
よくよく見れば言いたいことは分かるのですが、めちゃめちゃ目が滑ります。なので、torch.Tensor.scatter_の動作について、自分なりに整理したものをまとめてみました。
概要
この関数の動きは名前の通り、値を散りばめ (scatter) ます。
Tensor.scatter_(dim, index, src, reduce=None)
必須の引数は3つで、それぞれ以下のような役割を持っています。(reduceはまだちゃんと調べていないので飛ばします)
- dim: 値を散りばめる方向
- index: 値を散りばめる位置
- src: 散りばめる値
とはいえ、これだけ書いてもなかなか理解しづらいところがありますので、動かしてみて実際の動作を確認してみます。
動きが理解しやすく、ぱっと見でわかりやすい2次元のデータから見ていくことにしました。
2次元データ
まずは入力となるinput, src, indexを準備します。
全て0の3×3のテンソルinputに、1~9の値が格納されたsrcの値を散りばめていきます。
ちなみに、この処理はinputの値そのものを変えるため、元の値を保持したい場合はcopyしておく必要があります。
import numpy as np import torch input = torch.zeros((3, 3)) src = torch.linspace(1, 9, 9).reshape(3, 3) index = torch.tensor([[0, 1, 2],[2, 0, 1],[1, 2, 0]]) # input # tensor([[0., 0., 0.], # [0., 0., 0.], # [0., 0., 0.]]) # # src # tensor([[1., 2., 3.], # [4., 5., 6.], # [7., 8., 9.]]) # # index # tensor([[0, 1, 2], # [2, 0, 1], # [1, 2, 0]])
dim=0
2次元データですので、dimは0と1を指定できます。まずはdim=0から。
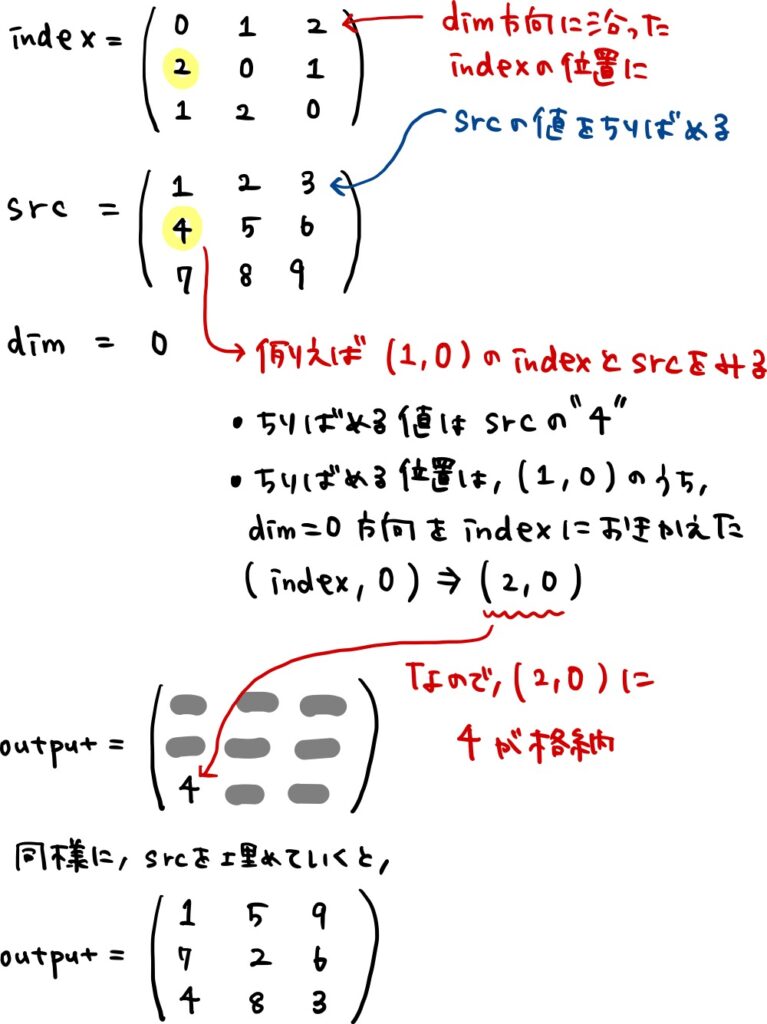
# dim=0 input.scatter_(0, index, src) # tensor([[1., 5., 9.], # [7., 2., 6.], # [4., 8., 3.]])
srcの値がdim=0方向に散らばったtensorが出力されました。
この動きを整理すると下の図のようになります(手書き文字ですので、読みづらかったらすみません)。
dim=1
次に、dim=1方向へ散りばめた場合を見てみます。
input.scatter_(1, index, src) # tensor([[1., 2., 3.], # [5., 6., 4.], # [9., 7., 8.]])
今度はdim=1方向にsrcの値が散らばっています。動きはdim=0のときと同じ考え方です。
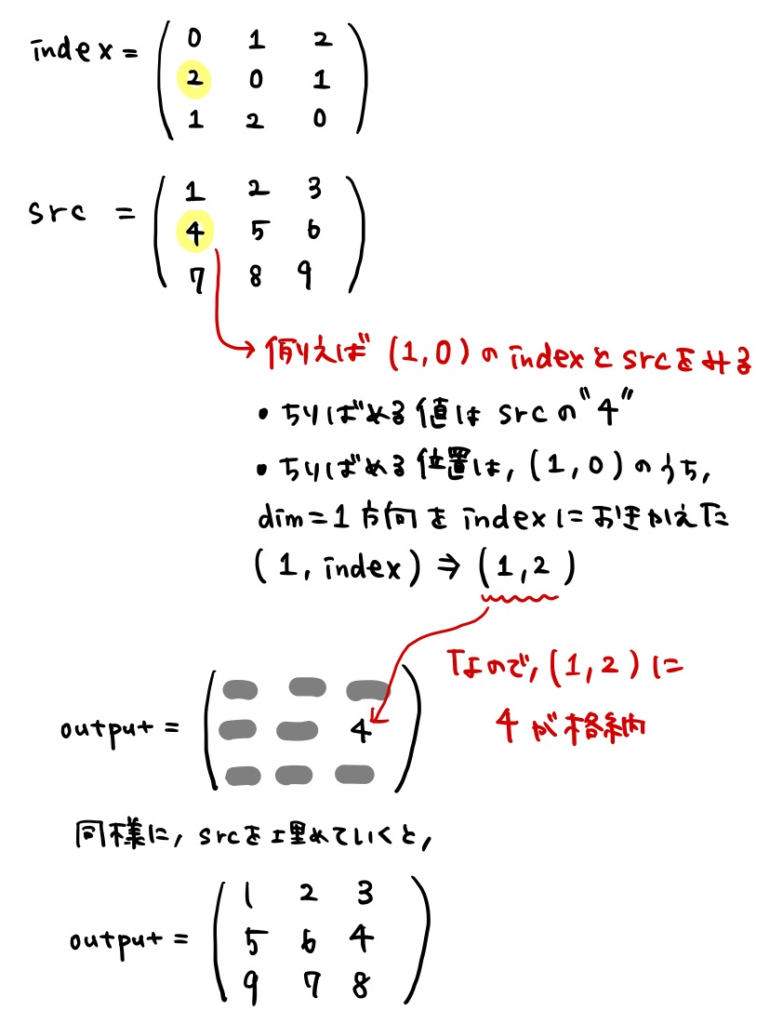
この動きを念頭に置けば、公式の動作の説明についてもなんとなく理解できるのではないでしょうか。
1次元データ
理屈が分かれば1次元は理解しやすくなります。同じく、全て0の1次元データにsrcを散りばめる処理を行ってみます。
入力を1次元で定義します。
input = torch.zeros((3)) src = torch.linspace(1, 3, 3) index = torch.tensor([0, 2, 1]) # input # tensor([0., 0., 0.]) # # src # tensor([1., 2., 3.]) # # index # tensor([0, 2, 1])
適用した結果です。
input.scatter_(0, index, src) # tensor([1., 3., 2.])
次元がひとつだけですので、だいぶ考えやすいですね。

スカラー値の埋め込み
この関数の使いどころとしては、one-hot-vectorを作るときや、フラグを立てるなどの場合がまず考えられるでしょうか。
one-hot-vector
まずは、one-hot-vectorです。1列に1つだけ1を格納するという処理を適用してみます。srcをテンソルではなく、スカラーとして与えます。
input = torch.zeros((3, 5)) src = 1 index = torch.tensor([[1], [0], [4]]) # input # tensor([[0., 0., 0., 0., 0.], # [0., 0., 0., 0., 0.], # [0., 0., 0., 0., 0.]]) # # src # 1 # # index # tensor([[1], # [0], # [4]])
出力結果です。列方向に指定したindex位置にのみ1が格納されました。
input.scatter_(1, index, src) # tensor([[0., 1., 0., 0., 0.], # [1., 0., 0., 0., 0.], # [0., 0., 0., 0., 1.]])
複数位置にフラグ
one-hot-vectorとほぼほぼ同じことですが、indexを複数指定してみます。
index = torch.tensor([[1,4], [0,2], [2,3]]) # tensor([[1, 4], # [0, 2], # [2, 3]])
こんな感じでひとつの列に複数の1が格納されました。
input.scatter_(1, index, src) # tensor([[0., 1., 0., 0., 1.], # [1., 0., 1., 0., 0.], # [0., 0., 1., 1., 0.]])
入力テンソルの制約
入力可能なinput/src/indexの形状・サイズを整理しました。
前提として、srcをテンソルとして与えた場合、input/src/indexの次元数は一致する必要があります。また、srcがスカラーの場合でも、input/indexの次元数は一致しなければなりません。
例として、2次元データを考えます。input, src, indexのデータサイズをそれぞれ、\(M_{in} \times N_{in}\)、\(M_{src} \times N_{src}\)、\(M_{idx} \times N_{idx}\)とすると、以下を満たす必要があります。
\(M_{in} \ge M_{src} \ge M_{idx} かつN_{in} \ge N_{src}\ge N_{idx}\)
indexはinputとsrcの「テンソルのどの位置」を使うかを直接指定しているため、外にはみ出た場合にエラーになるのは自然な考えかと思います。
srcがスカラーの時はsrcの制約がこの式から削除されるだけという感じですね。